5.17 The Human Genome
Created by: CK-12/Adapted by Christine Miller
Vitruvian Man
The drawing in Figure 5.17.1, named Vitruvian Man, was created by Leonardo da Vinci in 1490. It was meant to show normal human body proportions. Vitruvian Man is used today to represent a different approach to the human body. It symbolizes a scientific research project that began in 1990, exactly 500 years after da Vinci created the drawing. That project, called the Human Genome Project, is the largest collaborative biological research project ever undertaken.
What Is the Human Genome?
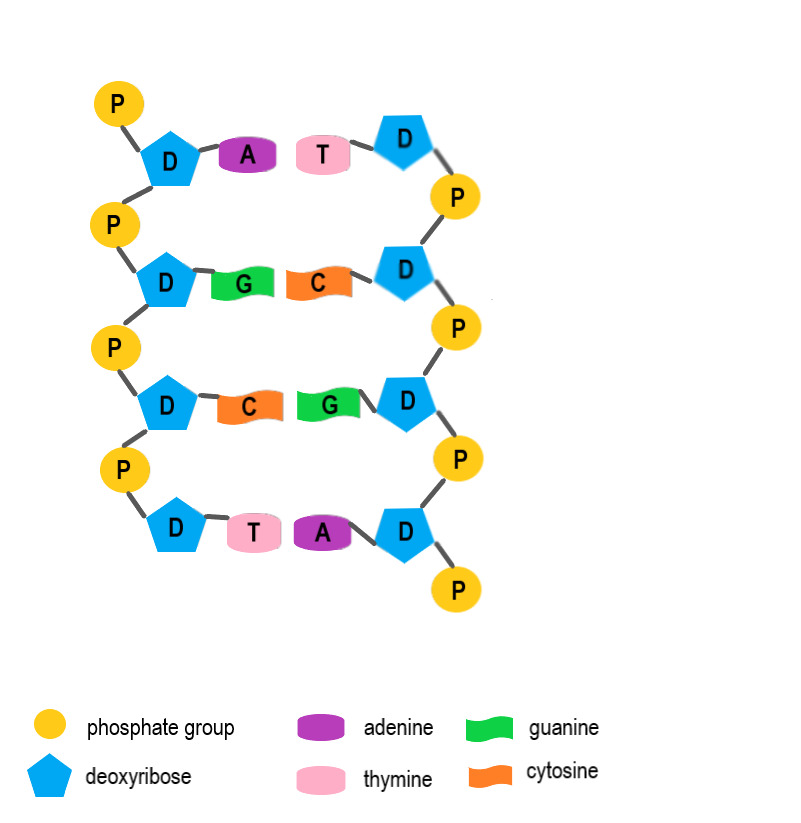
The human genome refers to all the DNA of the human species. Human DNA consists of 3.3 billion base pairs, and it is divided into more than 20 thousand genes on 23 chromosomes. Humans inherit one set of chromosomes from each parent. So there are actually two copies of each of those 20,000 genes. The human genome also includes noncoding sequences of DNA, as shown in Figure 5.17.2.
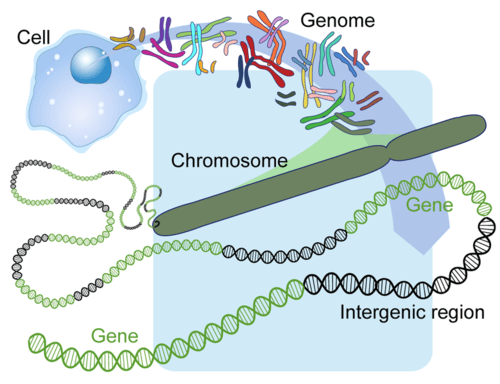
Discovering the Human Genome
Scientists now know the sequence of all the DNA base pairs in the entire human genome. This knowledge was attained by the Human Genome Project (HGP), a $3 billion, international scientific research project that was formally launched in 1990. The project was completed in 2003, two years ahead of its 15-year projected deadline.
Determining the sequence of the billions of base pairs that make up human DNA was the main goal of the HGP. Another goal was to map the location and determine the function of all the genes in the human genome. A somewhat surprising finding of the HGP is the relatively small number of human genes. There are only about 20,500 genes in human beings. This may sound like a lot, but it’s about the same number as in mice. Another surprising finding of the HGP is the large number of nearly identical, repeated DNA segments in the human genome. This number was previously believed to be much smaller.
A Collaborative Effort

Funding for the HGP came from the U.S. Department of Energy and the National Institutes of Health, as well as from foreign institutions. The actual research was undertaken by scientists in 20 universities in the U.S., United Kingdom, Australia, France, Germany, Japan, and China. A private U.S. company named Celera also contributed to the effort. Although Celera had hoped to patent some of the genes it discovered, this was later denied. The entire DNA sequence of the genome is stored in databases that are available to anyone on the Internet. Additional data and tools for analyzing the human genome are also available online.
Reference Genome of the Human Genome Project
In 2003, the HGP published the results of its sequencing of DNA as a human reference genome. The reference genome sequences a full set of human chromosomes, but it clearly doesn’t represent the sequence of every human individual’s genome. Instead, it is the combined mosaic of a small number of anonymous donors. The DNA that was sequenced came from blood samples of the female donors and sperm samples of the male donors. All of the donors were of European origin, and more than 70 per cent of the reference DNA came from a single anonymous male donor from Buffalo, New York. Identities of all the donors were protected so neither they nor the researchers could know whose DNA was sequenced.
Subsequent projects have sequenced the genomes of multiple distinct ethnic groups. Ongoing research is searching base by base for variations in the sequence. However, there is still only one reference genome available.
Benefits of the Human Genome Project
The sequencing of the human genome has benefits for many fields, including molecular medicine and human evolution.
- Knowing the human DNA sequence can help us understand many human diseases. For example, it is helping researchers identify mutations linked to different forms of cancer. It is also yielding insights into the genetic basis of cystic fibrosis, liver diseases, blood-clotting disorders, and Alzheimer’s disease, among others.
- The human DNA sequence can also help researchers tailor medications to individual genotypes. This is called personalized medicine, and it has led to an entirely new field called pharmacogenomics. Pharmacogenomics, also called pharmacogenetics, is the study of how our genes affect the way we respond to drugs. You can read more about pharmacogenomics in the Feature section below.
- The analysis of similarities between DNA sequences from different organisms is opening new avenues in the study of evolution. For example, analyses are expected to shed light on many questions about the similarities and differences between humans and our closest relatives, the nonhuman primates.
Ethical, Legal, and Social Issues of the Human Genome Project
From its launch in 1990, the HGP proactively established and funded a separate committee to oversee potential ethical, legal, and social issues associated with the project. Some of these possible issues include:
- The possible use of the knowledge generated by the project to discriminate against people. There were worries that that employers and health insurance companies would refuse to hire or insure people based on their genetic makeup, for instance, if they had genes that increased their risk of getting certain diseases.
- The issues surrounding “ownership” of DNA sequences. There have been requests by the both governmental agencies and private companies for patents of certain sequences of human genes called cDNA, although the US Patent Office has rejected all applications.
- Education of healthcare professionals, policy makers and the public about the complex issues involved in the HGP and what is done with the information acquired from it.
Feature: Human Biology in the News
Not everyone responds to medications in the same way. A drug that works well for one person may not be effective for another. The dose of a drug that cures a disease in one individual may be inadequate for someone else. Some people may experience side effects from a given medication, whereas other people do not. This variation in responses to medications can be due to differences in our genes. That’s where the field of pharmacogenetics comes in. News media have hailed it as the “new frontier in medicine.” It certainly seems to hold promise for improving the treatment of patients with pharmaceutical drugs.
Pharmacogenomics is based on a special kind of genetic testing. It looks for small genetic variations that influence a person’s ability to activate and deactivate drugs. Results of the tests can help doctors choose the best drug and most effective dose for a given patient. Some of the greatest successes of pharmacogenomics have been in cancer treatment. Many of the drugs that treat cancer need to be activated by the patient’s own enzymes. Inherited variations in enzymes may affect how quickly or efficiently the drugs are activated. For example, if a patient’s enzymes break down a particular drug too slowly, then standard doses of the drug may not work very well for that patient. Drugs also must be deactivated to reduce their effects on healthy cells. If a patient’s enzymes deactivate a drug too slowly, then the drug may remain at high levels and cause side effects.
One of the main benefits of pharmacogenomics is greater patient safety. Pharmacogenomic testing may help identify patients who are likely to experience adverse reactions to drugs, so that different, safer drugs can be prescribed. Another benefit of pharmacogenomics is eliminating the trial-and-error approach that is often used to find appropriate medications and doses for a given patient. This saves time and money, as well as improving patient outcomes.
Because pharmacogenomics is new, some insurance companies do not cover it, and it can be very expensive. Also, not all of the genetic tests are widely available at this point. In addition, there may be ethical and legal issues associated with the genetic testing, including concerns about privacy issues.
5.17 Summary
- The human genome refers to all of the DNA of the human species. It consists of more than 3.3 billion base pairs divided into 20,500 genes on 23 pairs of chromosomes.
- The Human Genome Project (HGP) was a multi-billion dollar international research project that began in 1990. By 2003, it had sequenced all of the DNA base pairs in the human genome. It also mapped the location and determined the function of all the genes in the human genome.
- In 2003, the HGP published the results of its sequence of DNA as a human reference genome. The entire DNA sequence is stored in databases that are available to anyone on the Internet.
- Sequencing of the human genome is helping researchers better understand cancer and genetic diseases. It is also helping them tailor medications to individual patients, which is the focus of the new field of pharmacogenomics. In addition, it is helping researchers better understand human evolution.
- From its launch in 1990, the HGP established and funded a separate committee to oversee potential ethical, legal, and social issues associated with the project.
5.17 Review Questions
- Describe the human genome.
- What is the Human Genome Project?
- Identify two main goals of the Human Genome Project.
- What is the reference genome of the Human Genome Project? What is it based on?
- Explain how knowing the sequence of DNA bases in the human genome is beneficial for molecular medicine.
- What was one surprising finding of the Human Genome Project?
- Why do you think scientists didn’t just sequence the DNA from a single person for the Human Genome Project? Along those lines, why do you think it is important to include samples from different ethnic groups and genders in genome sequencing efforts?
- What is pharmacogenomics?
- If a patient were to have pharmacogenomics done to optimize their medication, what do you think the first step would be?
- List one advantage and one disadvantage of pharmacogenomics.
- Explain how the sequencing of the human genome relates to ethical concerns about genetic discrimination.
5.17 Explore More
The race to sequence the human genome – Tien Nguyen, TED-Ed, 2015.
How to read the genome and build a human being | Riccardo Sabatini, TED, 2016.
Personalized Medicine: A New Approach | Luigi Boccuto | TEDxGreenville,
TEDx Talks, 2017.
Attributions
Figure 5.17.1
Vitruvian_man (black and white copy) by Leonardo Da Vinci, 1490, by Ianbond on Wikimedia Commons is released into the public domain (https://en.wikipedia.org/wiki/Public_domain).
Figure 5.17.2
Human Genome by CK-12 Foundation is used under a CC BY-NC 3.0 (https://creativecommons.org/licenses/by-nc/3.0/) license.
![]() ©CK-12 Foundation Licensed under
©CK-12 Foundation Licensed under ![]() • Terms of Use • Attribution
• Terms of Use • Attribution
Figure 5.17.3
Human genome_bookcase by Russ London at English Wikipedia is used under a CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0/deed.en) license.
References
Brainard, J/ CK-12 Foundation. (2016). Figure 2 Human genome, chromosomes, and genes. [digital image]. In CK-12 College Human Biology (Section 5.16) [online Flexbook]. CK12.org. https://www.ck12.org/book/ck-12-college-human-biology/section/5.16/
National Human Genome Research Institute (NHGRI). (n.d.). The Human Genome Project (HGP). National Institute of Health (NIH) /US Government. https://www.genome.gov/human-genome-project
TED. (2016, May 24). How to read the genome and build a human being | Riccardo Sabatini. YouTube. https://www.youtube.com/watch?v=s6rJLXq1Re0&t=2s
TED-Ed. (2015, October 12). The race to sequence the human genome – Tien Nguyen. YouTube. https://www.youtube.com/watch?v=AhsIF-cmoQQ&t=7s
TEDx Talks. (2017, June 8). Personalized medicine: A new approach | Luigi Boccuto | TEDxGreenville. https://www.youtube.com/watch?v=J2ITkfzp0SY&t=4s
Wikipedia contributors. (2020, April 18). Celera Corporation. In Wikipedia. https://en.wikipedia.org/w/index.php?title=Celera_Corporation&oldid=951693886
Wikipedia contributors. (2020, July 6). Human Genome Project. In Wikipedia. https://en.wikipedia.org/w/index.php?title=Human_Genome_Project&oldid=966272762
Wikipedia contributors. (2020, July 12). Leonardo da Vinci. In Wikipedia. https://en.wikipedia.org/w/index.php?title=Leonardo_da_Vinci&oldid=967303882
Wikipedia contributors. (2020, May 19). Vitruvian Man. In Wikipedia. https://en.wikipedia.org/w/index.php?title=Vitruvian_Man&oldid=957472578
The smallest particle of an element that still has the properties of that element.
By Christine Miller
DNA Replication: Overview
DNA replication is required for the growth or replication of an organism. You started as one single cell and are now made up of approximately 37 trillion cells! Each and every one of these cells contains the exact same copy of DNA, which originated from the first cell that was you. How did you get from one set of DNA, to 37 million sets, one for each cell? Through DNA replication.
Knowledge of DNA’s structure helped scientists understand DNA replication, the process by which DNA is copied. It occurs during the synthesis (S) phase of the eukaryotic cell cycle. DNA must be copied so that each new daughter cell will have a complete set of chromosomes after cell division occurs.
DNA replication is referred to as "semi-conservative". What this means is when a strand of DNA is replicated, each of the two original strands acts as a template for a new complementary strand. When the replication process is complete, there are two identical sets of DNA, each containing one of the original strands of DNA, and one newly synthesized strand.
DNA replication involves a certain sequence of events. For each event, there is a specific enzyme which facilitates the process. There are four main enzymes that facilitate DNA replication: helicase, primase, DNA polymerase, and ligase.
DNA Replication: The Process
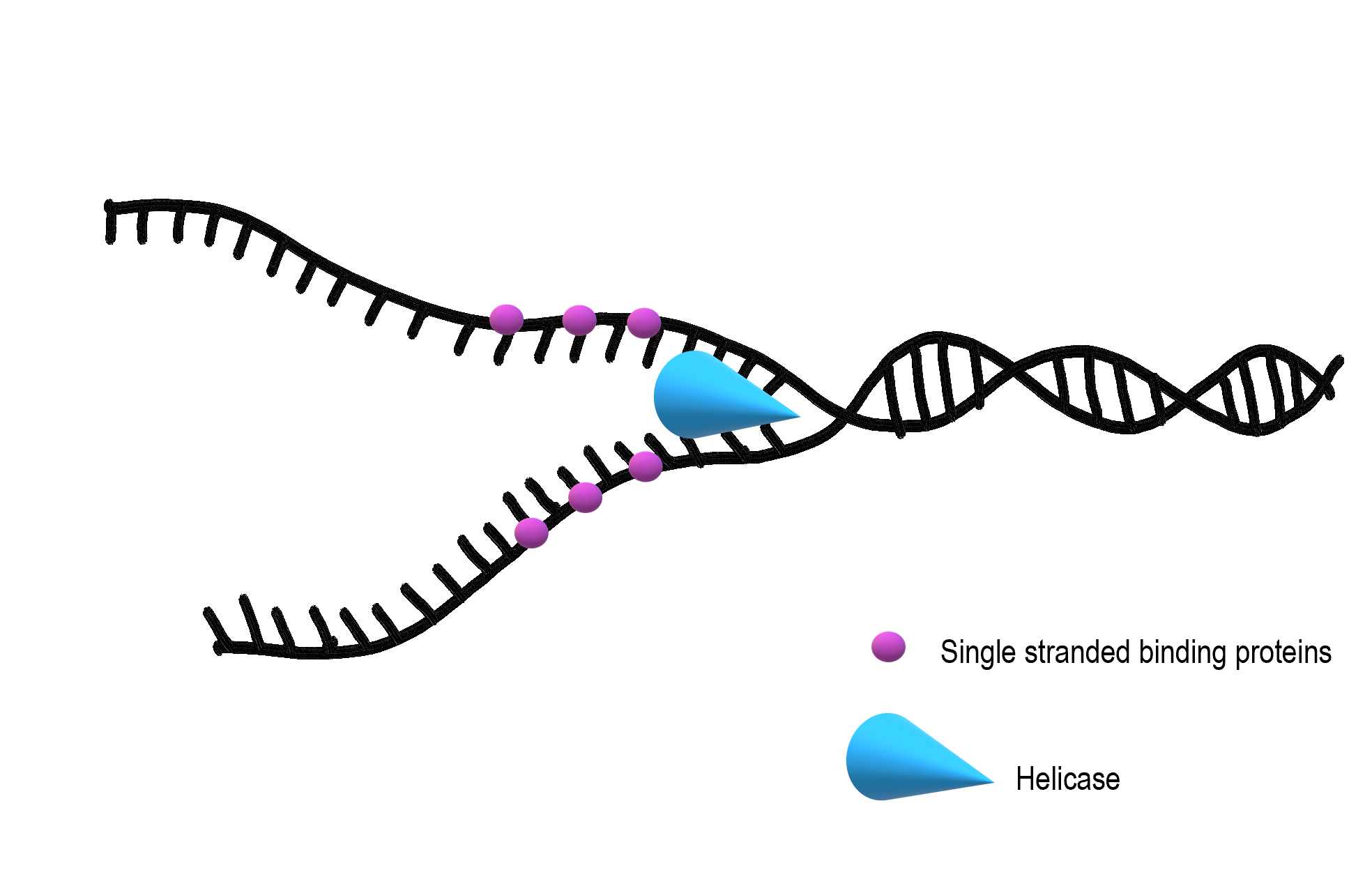
DNA replication begins when an enzyme called helicase unwinds, and unzips the DNA molecule. If you recall the structure of DNA, you may remember that it consists of two long strands of nucleotides held together by hydrogen bonds between complementary nitrogenous bases. This forms a ladder-like structure which is in a coiled shape. In order to start DNA replication, helicase needs to unwind the molecule and break apart the hydrogen bonds holding together complementary nitrogenous bases. This causes the two strands of DNA to separate.
Small molecules called single-stranded binding proteins (SSB) attach to the loose strands of DNA to keep them from re-forming the hydrogen bonds that helicase just broke apart.
Once the nitrogenous bases from the inside of the DNA molecule are exposed, the creation of a new, complementary strand can begin. DNA polymerase creates the new strand, but it needs some help in finding the correct place to begin, so primase lays down a short section of RNA primer (shown in green in Figure 5.4.3). Once this short section of primer is laid, DNA polymerase can bind to the DNA molecule and start connecting nucleotides in the correct order to match the sequence of nitrogenous bases on the template (original) strand.
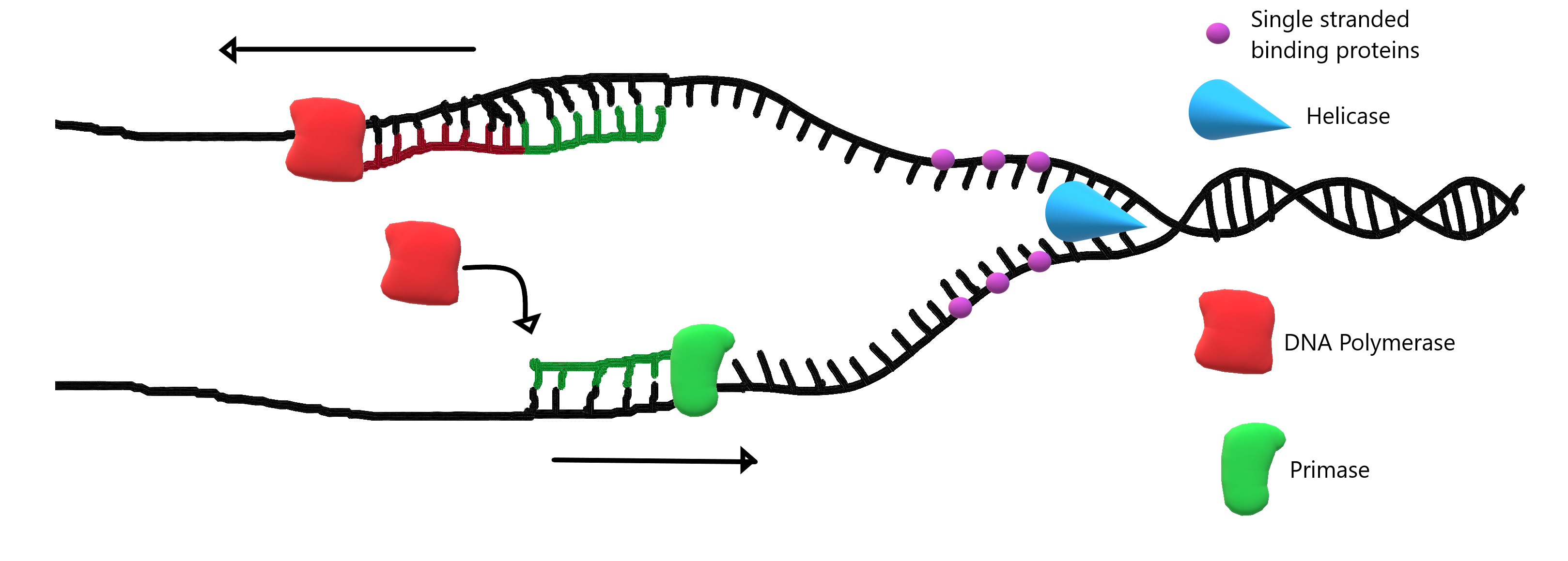
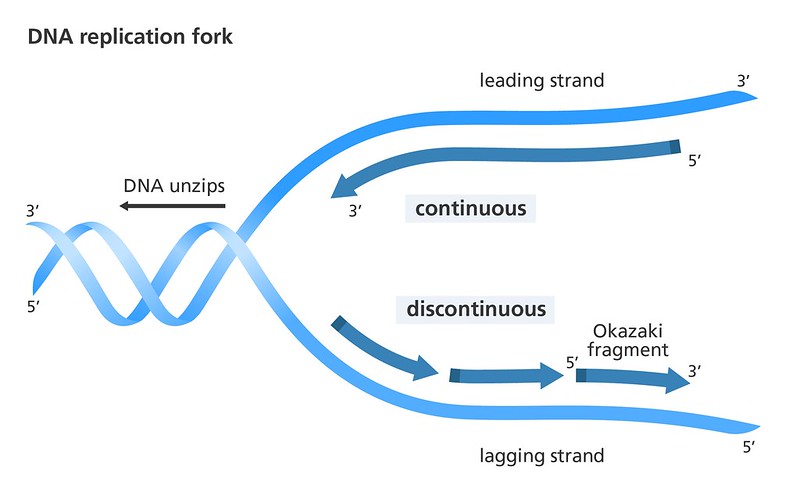
If we think about the DNA molecule, we may remember that the two strands of DNA run antiparallel to one another. This means that in the sugar-phosphate backbone, one strand of the DNA has the sugar oriented in the "up" position, and the other strand has the phosphate oriented in the "up" position (see Figure 5.4.4). DNA polymerase is an enzyme which can only work in one direction on the DNA molecule. This means that one strand of DNA can be replicated in one long string, as DNA polymerase follows helicase as it unzips the DNA molecule. This strand is termed the "leading strand". The other strand, however, can only be replicated in small chunks since the DNA polymerase replicates in the opposite direction that helicase is unzipping. This strand is termed the "lagging strand". These small chunks of replicated DNA on the lagging strand are called Okazaki fragments.
Take a look at Figure 5.4.5 and find the Okazaki fragments, the leading strand and the lagging strand.
Once DNA polymerase has replicated the DNA, a third enzyme called ligase completes the final stage of DNA replication, which is repairing the sugar-phosphate backbone. This connects the gaps in the backbone between Okazaki fragments. Once this is complete, the DNA coils back into its classic double helix structure.
Semi-Conservative Replication
When DNA replication is complete, there are two identical sets of double stranded DNA, each with one strand from the original, template, DNA molecule, and one strand that was newly synthesized during the DNA replication process. Because each new set of DNA contains one old and one new strand, we describe DNA as being semi-conservative.
Watch this video for a great overview of DNA replication:
https://www.youtube.com/watch?v=Qqe4thU-os8
DNA Replication (Updated), Amoeba Sisters, 2019.
5.4 Summary
- DNA replication requires the action of three main enzymes each with their own specific role:
- Helicase unzips and unwinds the DNA molecule.
- DNA polymerase creates a new complementary strand of DNA on each of the originals halves that were separated by helicase. New nucleotides are added through complementary base pairing: A pairs with T, and C with G.
- Ligase repairs gaps in the sugar-phosphate backbone between Okazaki fragments.
- DNA replication is semi-conservative because each daughter molecule contains one strand from the parent molecule and one new complementary strand.
5.4 Review Questions
2. Why are Okazaki fragments formed?
- Because helicase only unzips DNA in one direction.
- Because DNA is in a double helix.
- Because DNA polymerase only replicates DNA in one direction.
- Because DNA replication is semi-conservative.
3. Drag and drop to label the diagram.
5.4 Explore More
https://www.youtube.com/watch?v=TNKWgcFPHqw
DNA replication - 3D, yourgenome, 2015.
Attributions
Figure 5.4.1
DNA_replication_split.svg by Madprime on Wikimedia Commons is used under a CC0 1.0
Public Domain Dedication license (https://creativecommons.org/publicdomain/zero/1.0/deed.en).
Figure 5.4.2
Helicase and single stranded binding proteins (1) by Christine Miller is used under a CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/) license.
Figure 5.4.3
DNA polymerase and primase by Christine Miller is used under a CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/) license.
Figure 5.4.4
DNA strands run antiparallel by Christine Miller is used under a CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/) license.
Figure 5.4.5
Leading and lagging strand/ DNA Replication/ by yourgenome on Flickr is used under a CC BY-NC-SA 2.0 (https://creativecommons.org/licenses/by-nc-sa/2.0/) license.
References
Amoeba Sisters. (2019, June 28). DNA replication (Updated). YouTube. https://www.youtube.com/watch?v=Qqe4thU-os8&feature=youtu.be
Betts, J. G., Young, K.A., Wise, J.A., Johnson, E., Poe, B., Kruse, D.H., Korol, O., Johnson, J.E., Womble, M., DeSaix, P. (2013, April 25). Figure 3.24 DNA Replication [digital image]. In Anatomy and Physiology. OpenStax. https://openstax.org/books/anatomy-and-physiology/pages/3-3-the-nucleus-and-dna-replication CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/)
yourgenome. (2015, June 26). DNA replication - 3D. YouTube. https://www.youtube.com/watch?v=TNKWgcFPHqw&feature=youtu.be

{kind=link}
{kind=link}
{kind=link}