Normal Distributions
The Empirical Rule, Outliers and Excel’s NORM.DIST()
Learning Objectives
Use the Empirical Rule and Excel's NORM.DIST() function to calculate probabilities.
Empirical Rule
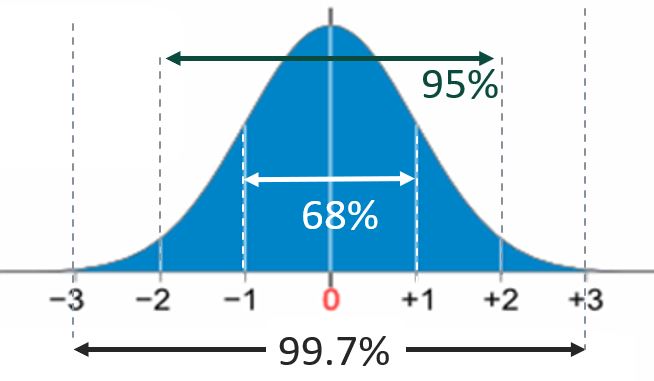 |
When data are Normally Distributed:
|
Outliers
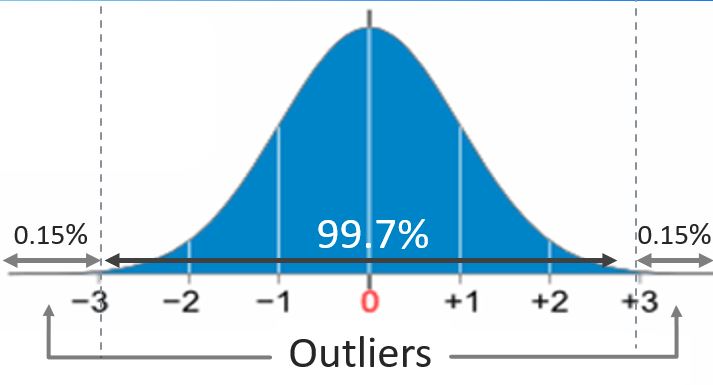 |
|
Applying the Empirical Rule (Exercises)
Let us first try some examples/exercises where we will seek to understand the Empirical Rule percentages. This understanding will also help when calculating more complicated probabilities using Excel's NORM.DIST() function in later sections.
Example 39.1
Problem Setup: In this problem, we will 'divide up' the sections of the normal curve into 'slices'.
Question: Can you figure out the percent of data that lie in each slice of the curve?
You try: Drag the appropriate percentage into each slice in the exercise below:
Need Help? Try the exercise below first.
Example 39.2
Problem Setup: Demand for the 12-pack of extra plush toilet paper follows a normal distribution at a local drug store. On average, they sell 50 packs per week with a standard deviation of 10 packs. They get deliveries once per week and stock 80 packs of toilet paper per week.
Question: Can you solve for the probabilities below and match them to their answers?
Need Help? Click on the problems below to reveal their answers:
Probability of 40 to 60 packs sold
We are given the following values in the problem:
- μ = 50, σ = 10, x1 = 40, x2 = 60
- z1 = (40−50)/10 = −10/10 = −1
- z2 = (60−50)/10 = 10/10 = 1
This gives P(40 < x < 60) = 34% + 34% = 68% (see below):
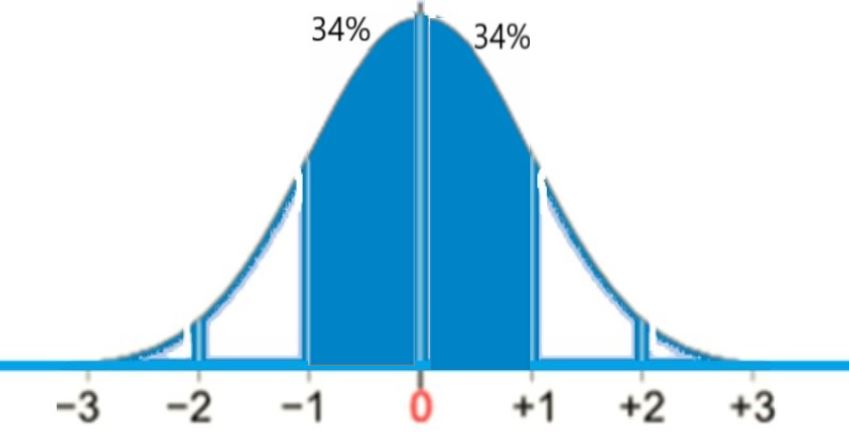
probability of 30 and 70 packs sold
We are given the following values in the problem:
- μ = 50, σ = 10, x1 = 30, x2 = 70
- z1 = (30−50)/10 = −20/10 = −2
- z2 = (70−50)/10 = 20/10 = 2
This gives P(30 < x < 70) = 13.5% + 34% + 34% + 13.5% = 95% (see below):
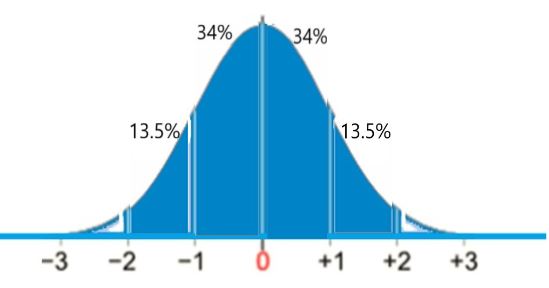
probability of 30 and 80 packs sold
We are given the following values in the problem:
- μ = 50, σ = 10, x1 = 30, x2 = 80
- z1 = (30−50)/10 = −20/10 = −2
- z2 = (80−50)/10 = 30/10 = 3
This gives P(30 < x < 80) = 13.5% + 34% + 34% + 13.5% + 2.35% = 97.35% (see below):
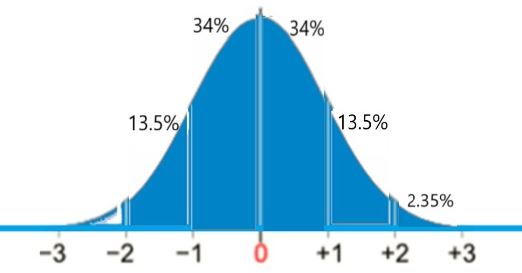
probability of Less than 20 packs sold
We are given the following values in the problem:
- μ = 50, σ = 10, x = 20
- z = (20−50)/10 = −30/10 = −3
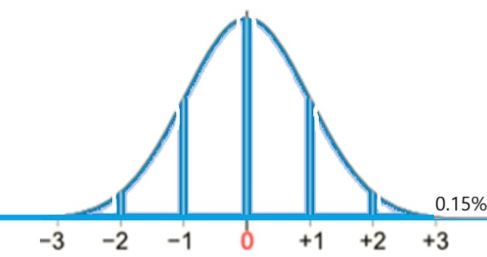
This gives P(x < 20) = 0.15% (see below):
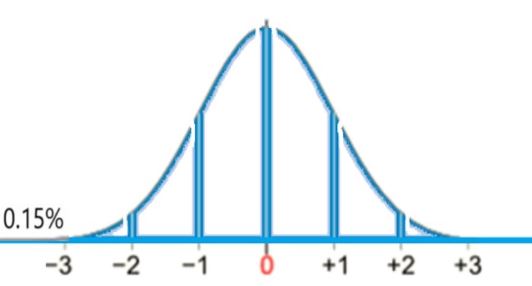
probability of Greater than 50 packs sold
We are given the following values in the problem:
- μ = 50, σ = 10, x1 = 30, x = 50
- z = (50−50)/10 = 0/10 = 0
This gives P(x > 50) = 34% + 13.5% + 0.15% = 50% (see below):
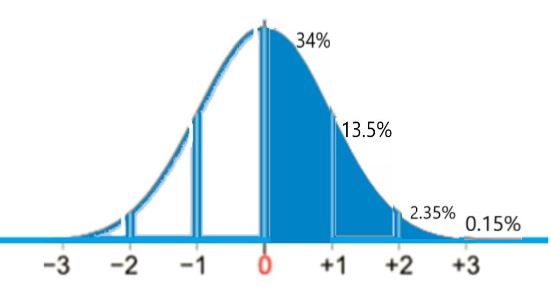
Conclusion: We see that the area above the mean (z=0) makes up half (50%) of the graph.
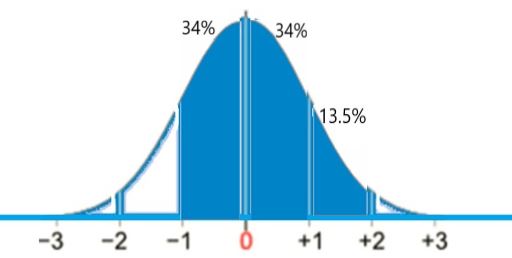
probability of 40 and 70 packs sold
We are given the following values in the problem:
- μ = 50, σ = 10, x1 = 40, x2 = 70
- z1 = (40−50)/10 = −10/10 = −1
- z2 = (70−50)/10 = 20/10 = 2
This gives P(40 < x < 70) = 34% + 34% + 13.5% = 81.5% (see below):
probability Of stocking out
If we stock out, demand is higher than supply. We stock 80 packs per week. This means that demand is higher than 80 packs that week:
- μ = 50, σ = 10, x = 80
- z = (80−50)/10 = 30/10 = 3
This gives P(x > 80) = 0.15% (see below):
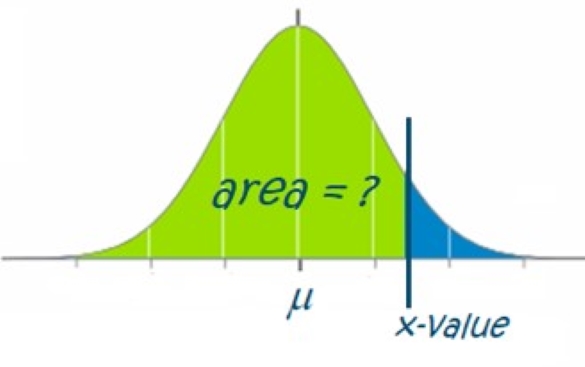
Calculating the Area Below an X-Value (Norm.DIST Exercise)
Let us now practice using Excel's NORM.DIST() function to solve for probabilities. Remember the following is true when calculating the area below an [latex]x[/latex]-value:
 |
|
Example 39.3.1
Problem Setup: A school's SAT scores are normally distributed with a mean of 1,010 and standard deviation of 20.
Question: What percent of students have scores below 1,040 points?
You try 1: Drag the region we would highlight for this question onto the graph below:
You try 2: Select the correct Excel formula and resulting solution for this question:
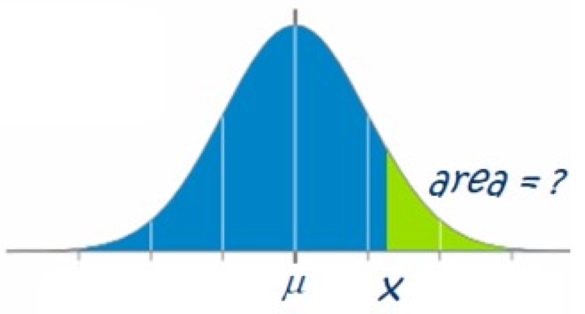
Calculating the Area Above an X-Value (Norm.DIST Exercise)
Remember, the following is true when calculating the area above an [latex]x[/latex]-value:
 |
|
Example 39.3.2
Problem Setup: Let us keep going with our previous example of average SAT scores of 1,010 with a standard deviation of 20.
Question: What percent of students score above 1,040 on their SATs?
You try 1: Drag the region we would highlight for this question onto the graph below:
You try 2: Select the correct Excel formula and resulting solution for this question:
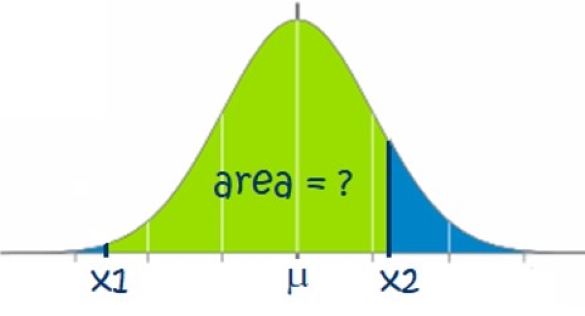
Calculating the Area Between Two X-Values (Norm.DIST Exercise)
Remember, the following is true when calculating the area between two [latex]x[/latex]-values:
 |
|
Example 39.3.3
Problem Setup: Let us, again, keep going with our previous example with average SAT scores of 1,010 with a standard deviation of 20.
Question: What percent of students score between 955 and 1,035 on their SATs?
You try 1: Drag the region we would highlight for this question onto the graph below:
You try 2: Select the correct Excel formula and resulting solution for this question:
Need more help? See the video in the section below for a full walk-through of these examples
Video & Additional Resources Explaining this section
Additional Resources:
- Click here to download the Powerpoint slides that accompany the video.
- Click here to download the Excel solutions for the Normal Distribution section.
Key Takeaways (EXERCISE)
Key Takeaways: The Empirical Rule, Outliers and Using Excel's NORM.DIST
Drag the words into the correct boxes for each section below:
Click the sections below to reveal the solutions to the above exercises
Your Own Notes (EXERCISE)
- Are there any notes you want to take from this section? Is there anything you'd like to copy and paste below?
- These notes are for you only (they will not be stored anywhere)
- Make sure to download them at the end to use as a reference
