Nucleic Acids
Nucleic acids are biological polymers of a monomer called nucleotides. Nucleotides consist of a pentose sugar covalently bound to a negatively charged phosphate and a nitrogenous base. There are five common nitrogenous bases: adenine (A), thymine (T), guanine (G), cytosine (C), and uracil (U). When nucleotides are incorporated into a growing nucleic acid by dehydration synthesis, the sugar-phosphates of adjacent nucleotides are linked by covalent bonds called phosphodiester bonds.
Two biologically important nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA and RNA are both important nucleic acids in cells, but they differ by several structural characteristics. First, the pentose sugar of all nucleotides that comprise DNA is deoxyribose while the pentose sugar of all nucleotides that comprise RNA is ribose. Second, DNA contains only A, T, G, and C; RNA contains only A, U, G, and C. Third, DNA is double-stranded. This means that one chain of nucleotides always pairs with a second chain of nucleotides to form a unique double helix. In contrast, RNA is generally single-stranded, meaning one chain of nucleotides folds on itself.
Chemistry in the clinic:
The double helical structure of DNA was determined by an X-ray crystallographer named Rosalind Franklin and published by her colleagues James Watson and Francis Crick. Watson, Crick, and Franklin’s supervisor Maurice Wilkins received the Nobel Prize in Physiology or Medicine in 1962 for their discovery of the double helical structure of DNA. Franklin died due to complications from ovarian cancer in 1958 and did not share in the Nobel Prize for her contribution to the discovery of DNA structure. The double helical structure of DNA was essential to understanding how DNA copies itself or replicates and how other cellular molecules such as proteins interact with DNA.

The DNA double helix consists of two nucleotide chains or strands that face opposite directions. The antiparallel arrangement of DNA strands is stabilized by chemical bonds that link the nitrogenous bases of adjacent strands together. Think of the DNA double helix as a winding staircase: the sugar-phosphate portions of the nucleotides form the “rails” while the nitrogenous bases face inward toward one another and form the “stairs”. The nitrogenous bases pair in a specific manner: A always pairs with T and G always pairs with C. These nitrogenous bases are held together by hydrogen bonds. The discovery of the double helical structure of DNA helped scientists answer an important question: how DNA was copied or replicated.
The function of DNA is to provide instructions to cells on how to build that exact same cell. Before cells divide, they must replicate their DNA so that the daughter cell receives a full copy of the genetic instructions. During DNA replication, the DNA double helix is unwound and the hydrogen bonds between base pairs is disrupted. Each strand serves as a template for cellular enzymes to create a complementary strand of DNA. Complementary strands do not have the same sequence as the template. Instead, cellular enzymes use the pairing rules of nitrogenous bases to complete a new daughter strand of DNA: if the template strand contains an A base, then enzymes will insert a T in the new molecule. If the template strand contains a G, then enzymes will insert a C in the new strand. As a result, each resulting daughter molecule from DNA replication contains one “old” template strand and one “new” strand. This type of DNA replication is known as semi-conservative DNA replication. Understanding the double helical structure of DNA provided scientists with a clue as to how semi-conservative DNA replication proceeds.
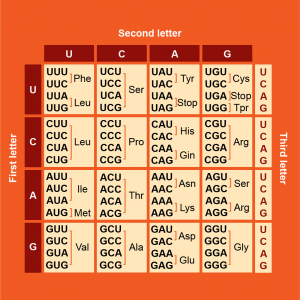
Short DNA sequences that provide instructions for the cell to make a protein are called genes. In human cells, genes are transcribed by enzymes into a special set of RNA molecules called messenger RNA (mRNA) in the cell nucleus. The mRNA exits the nucleus and is bound by molecular machines called ribosomes in the cytosol or on the rough endoplasmic reticulum. You will examine these organelles in a later unit of the course. Translation of mRNA into peptides by ribosomes produces a protein. The sequence of nucleotides in genes determines the mRNA sequence and, therefore, the amino acid sequence of the encoded protein. Changes to the identity of nucleotides within a DNA sequence are called mutations. Mutations in DNA may change the amino acid sequence of proteins, resulting in different protein function. This flow of information within cells from the DNA of genes through an mRNA intermediate to a translated protein is known as the central dogma of biology.
RNA, therefore, functions as a transcript of the protein-encoding messages in genes. RNA also forms a part of ribosomes (ribosomal RNA or rRNA) and molecules that bring amino acids to ribosomes to assist with mRNA translation (transfer RNA or tRNA).
Together, the nucleic acids of the cell — DNA and RNA — provide the cell with instructions to make proteins and those proteins determine the characteristics and functions of the cell.