9 Non-inferiority trials: Was the intervention compared to see if it is “no worse” than an established therapy?
Most commonly trials test for superiority i.e. determining whether an intervention is superior to some comparator with respect to the primary outcome. Conversely, the objective of a non-inferiority trial is to test whether an intervention is “not much worse” than a comparator (usually the current standard of care) with regard to the primary outcome. The rationale for a non-inferiority design is that the new treatment offers some benefit other than increased efficacy, such as being safer, more affordable, or more convenient. While the fundamentals of non-inferior trials are similar to that of superiority trials, there are some unique concepts necessary when critically appraising them.
Non-Inferiority Margins
The non-inferiority margin is closely related to the minimally important difference, which is the smallest difference in the effect on an outcome that would be meaningful to a representative group of patients. The non-inferiority margin is the yardstick by which non-inferiority is defined, and is selected during the design of a non-inferiority trial. If the CI of the difference between the intervention and comparator crosses the non-inferiority margin, the intervention is deemed to not be non-inferior to the comparator. For example, consider a non-inferiority margin is a RR of 1.2 for stroke, and the actual RR is 0.9 with 95% CI 0.5 to 1.3. Since the observed upper end of the CI (1.3) is greater than the non-inferiority margin (>1.2), the conclusion is that the treatment is not non-inferior. If the upper end of the CI had been 1.1, the conclusion would be that the treatment is non-inferior given that 1.1 < 1.2.
Intuitively this should be equivalent to the minimally important difference, and ideally this is the case; however, researchers may choose a more “generous” non-inferiority margin (i.e. one that allows a difference greater than the minimally important difference to be considered “not much worse”).
See the graphical depiction of concept below:
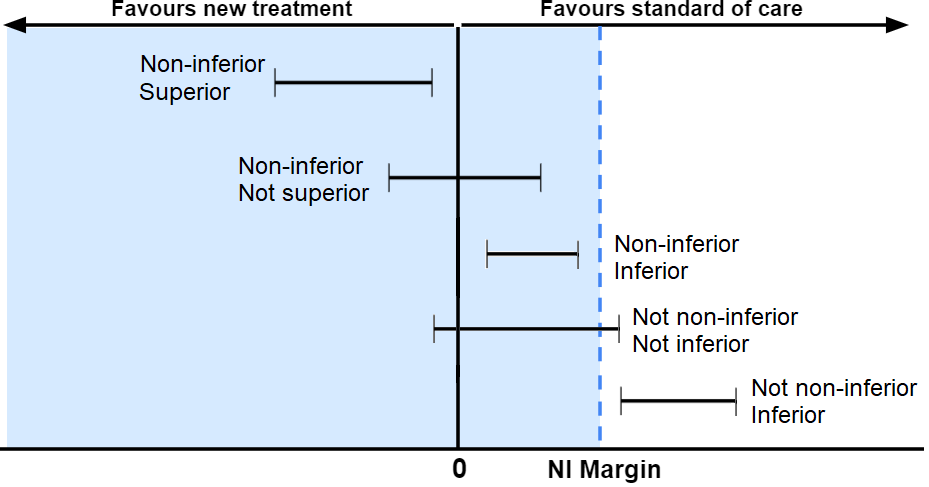
Plot 6. Graphical depiction of non-inferiority and related concepts.
Superiority and inferiority (consider the line of no difference):
- The treatment is considered superior when the upper end of the CI is below the line of no difference (0 in this case).
- The treatment is considered inferior when the lower end of the CI is above the line of no difference.
Non-inferiority and not non-inferiority (consider the non-inferiority margin):
- The treatment is considered non-inferior when the upper end of the CI falls to the left of the non-inferiority margin.
- The treatment is considered not non-inferior when the CI crosses to the right of the non-inferiority margin.
See Mulla SM et al. for more information on the questions asked below. See Hong J et al. for information concerning deficits in non-inferiority trial reporting.
Checklist Questions
| Is a non-inferiority design justified by some other advantage of the intervention versus the comparator? |
| Did the trial use a non-inferiority margin based on a relative or an absolute risk difference? |
| Is the non-inferiority margin well justified based on statistical reasoning and clinical judgment? |
| Is the non-inferiority margin strict enough according to your own judgment? |
| Was non-inferiority demonstrated in both intention-to-treat (ITT) and per protocol analyses? |
| Was the comparator appropriate? |
| Has the active comparator demonstrated unequivocal superiority over placebo in previous trials? |
| Was the effect of the comparator in this trial consistent with that of previous trials? |
Is the non-inferiority design justified by some other advantage of the intervention versus the comparator?
If the intervention is non-inferior but not superior, it should have another meaningful advantage that justifies considering it for your patients. Consider and quantify:
- Fewer, less frequent, or less-severe adverse effects
- Fewer drug interactions
- Easier to take
- Less intensive or less invasive monitoring required
- Lower cost
Note: The advantage of the non-inferior intervention should not be included in the primary outcome being tested for non-inferiority. This biases the results in favor of the new intervention.
E.g. In PRAGUE-17 (Osmancik P et al.), a RCT comparing percutaneous left atrial appendage occlusion (LAAO) with direct-acting oral anticoagulants (DOACs) in patients with atrial fibrillation and a history of bleeding, the primary outcome was a composite of:
- Ischemic or hemorrhagic stroke
- Transient ischemic attack
- Systemic embolism
- Cardiovascular death
- Procedure-/device-related complications
- Major or non-major clinically relevant bleeding
However, since the justification to see if LAAO was non-inferior to DOACs was that LAAO may offer a lower risk of bleeding, it was inappropriate to include bleeding in the primary outcome being tested for non-inferiority. Indeed, bleeding events accounted for nearly half of all primary outcome events, and excluding these would not allow for the conclusion of non-inferiority (LAAO would be “not non-inferior” to DOAC).
Did the trial use a non-inferiority margin based on a relative or an absolute risk difference?
- Non-inferiority margins based on absolute risk scales can falsely conclude an intervention to be non-inferior if event rates are lower than expected, which commonly occurs
- Relative risk non-inferiority margins are more conservative – and therefore preferable – as they scale to the incidence of outcomes in the trial
Is the non-inferiority margin well justified based on statistical reasoning and clinical judgment?
A trial’s non-inferiority margin should be justified on the principle that the intervention being studied is (1) “not much worse” than (non-inferior to) the comparator, and (2) still better than nothing/placebo. Rules for an appropriate non-inferiority margin:
- Defined prior to undertaking the trial
- Justified relative to the minimal important difference (previously termed the minimal clinically important difference), which should be defined based on prior evidence
- Preserve the effect of the standard treatment over placebo
Is the non-inferiority margin strict enough according to your own judgment?
Ultimately, you as the reader need to decide for yourself if the non-inferiority margin is reasonable and acceptable.
Note that the non-inferiority margin refers to an acceptable boundary for the “worst case” end of the CI, not the point estimate itself.
Was non-inferiority demonstrated in both intention-to-treat (ITT) and per protocol analyses?
- As is the case with superiority trials, ITT analysis is preferred as the primary analysis as it preserves the advantages of randomization and minimizes attrition bias. However, ITT may attenuate outcome differences between groups and make it easier to demonstrate non-inferiority.
- Per-protocol analysis aims to isolate the effect of the intervention by excluding patients who did not receive study treatment “per-protocol”, such as patients who dropped out or received the intervention intended for the other treatment group (“crossover”). In many cases, dropouts and crossovers are due to intervention inefficacy/intolerance and/or associated with patient prognosis, which introduces bias. Some falsely believe that this makes the per-protocol analysis the more conservative analysis for non-inferiority trials; however, that is only the case if the bias that is introduced favors the comparator. In other words, using the per-protocol analysis where protocol violations or crossovers occur more frequently in the comparator group will bias the results in favor of concluding that the intervention is non-inferior.
- In most cases, discrepancies between ITT and per-protocol analyses suggest that bias has been introduced into the trial. As a general rule, non-inferiority should only be accepted/concluded if it is demonstrated in both the ITT and per-protocol analysis.
In a systematic review of 231 non-inferiority RCTs published in five high-impact journals from 2005 to 2014, only 45% of non-inferiority RCTs reported both ITT and per-protocol analyses. When both were reported, discrepancies between analyses (in terms of demonstrating non-inferiority) occurred in 6% of comparisons. Neither analysis was consistently more conservative, with the ITT being more conservative in 50% of discrepancies (Turgeon RD, Reid EK, et al.).
Was the comparator appropriate?
The comparator intervention should:
- Be consistent with the current standard of care. This can be assessed by scanning local institution policy and/or national guidelines
- Be more effective than nothing/placebo. This can be assessed by scanning tertiary references such as DynaMed and UpToDate for high-quality evidence demonstrating clinically important benefits of the comparator
- Have an effect that is consistent with that of previous trials
A superiority trial tests for whether an intervention has a greater effect than a comparator with respect to the primary outcome. This is contrasts with non-inferiority trials.
A primary outcome is an outcome from which trial design choices are based (e.g. sample size calculations). Primary outcomes are not necessarily the most important outcomes.
The minimum difference in a value that would be of importance to a patient. There are various methods of calculating a minimally important difference.
Relative risk (or risk ratio) is the risk in one group relative to (divided by) risk in another group. For example, if 10% in the treatment group and 20% in the placebo group have the outcome of interest, the relative risk in the treatment group is 0.5 (10% ÷ 20%; half) the risk in the placebo group. See here for a more detailed discussion.
Calculates the effect of an intervention via a fractional comparison with the comparator group (i.e. intervention group measure ÷ comparator group measure). Used for binary outcomes. Relative risk, odds ratio, or hazards ratio are all expressions of relative effect. For example, if the risk of developing neuropathy was 1% in the treatment group and 2% in the comparator group, then the relative risk is 0.5 (1 ÷ 2). See the Absolute Risk Differences and Relative Measures of Effect discussion here for more information.
Absolute risk difference is the risk in one group compared to (minus) the risk in another group over a specified period of time. For example, if the absolute risk of myocardial infarction over 5 years was 15% for the comparator and 10% for the intervention, then the absolute risk difference was 5% (15% - 10%) over 5 years. See here for further discussion.
Participant outcomes are analyzed according to their assigned treatment group, irrespective of treatment received. A common "modified ITT" approach used in pharmacotherapy trials considers only participants who received at least one dose of the study drug (thereby excluding participants who were randomized but did not receive any study intervention).
This type of analysis examines patients only if they sufficiently adhered to the treatment group in which they were assigned.
Systematic deviation of an estimate from the truth (either an overestimation or underestimation) caused by a study design or conduct feature. See the Catalog of Bias for specific biases, explanations, and examples.
Randomized controlled trials are those in which participants are randomly allocated to two or more groups which are given different treatments.
The difference between two relative risks (RRs). If the intervention has a RR of 70% and the comparator a risk of 100%, then the relative risk reduction is 30% (100% - 70%).
An outcome which consists of multiple component endpoints. For example, a cardiovascular composite may include stroke, myocardial infarction, and death.
A single value given as an estimate of the effect. For example, results may be listed as a relative risk of 0.5 (95% CI 0.4-0.6). In this case 0.5 is the point estimate, and 0.4-0.6 is the 95% confidence interval.
