6 Secondary outcomes: Can conclusions be made from outcomes other than the primary one?
Most trials designate one outcome as a "primary" outcome (or 2-3 “co-primary outcomes”) and all other outcomes as "secondary" outcomes. Designation of an outcome as “primary” is done to determine and justify sample size calculations prior to conducting a study. In other words, the primary outcome is not necessarily the most clinically important (it often isn’t), and should not be the sole consideration as to whether an intervention is “better” than a comparator.
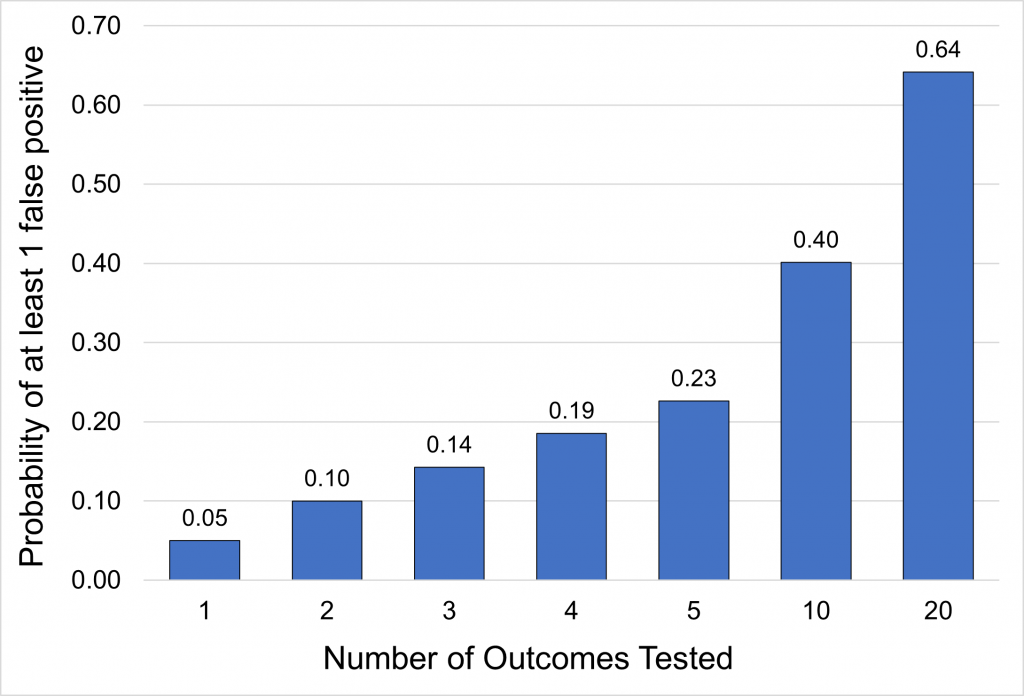
The interpretation of secondary outcomes requires additional considerations. The probability of finding a difference simply due to chance increases as the number of outcomes increases.
Checklist Questions
| Are we trying to find a difference in a secondary outcome when there was no statistically significant difference between groups for the primary outcome? |
| Was the secondary outcome one of a small number of secondary endpoints defined in the original protocol? If there was a positive finding, were there appropriate statistical adjustments made? |
| Does the secondary endpoint result make sense in the context of the primary (and other secondary) outcome findings? |
| Was there an unexpected positive finding for a rare outcome? |
Data-mining: Are we trying to find a difference in a secondary outcome when there was no statistically significant difference between groups for the primary outcome?
Authors may emphasize statistically significant differences in secondary outcomes when they fail to find a statistically significant difference in the primary outcome.
For example, a review (Khan MS et al.) of 93 cardiovascular RCTs found that spin (i.e. reporting strategies highlighting benefits despite a non-statistically significant primary outcome) was present in 57% of abstracts and 67% of main texts.
Minimizing multiplicity: Was the secondary outcome one of a small number of secondary endpoints defined in the original protocol? If there was a positive finding, were there appropriate adjustments made?
More comparisons increase the risk of finding a difference when there is none, as depicted:
Depending on the context, it may be justified to adjust for multiplicity when considering multiple outcomes. Adjusting for multiplicity is a statistical method of requiring lower p-values to account for multiple comparisons. There are multiple methods for calculating the stricter margin (Bonferroni test, Holm test, etc.). There is no consensus on when to adjust for multiplicity, but the following can act as general guidance:
| Circumstance | Whether Adjustment is Necessary |
| At least one outcome is positive and the outcome is intended to inform future research rather than be incorporated directly into clinical practice (i.e. exploratory) | Adjustments in the analysis are not warranted as such findings are used only to generate hypotheses |
| At least one outcome is positive and the outcome is intended to directly inform clinical practice (i.e. confirmatory) | Adjustments may be necessary if: – More than one dose is compared – More than one primary outcome is used – The primary outcome was assessed in multiple different population |
Consistency: Does the secondary endpoint result make sense in the context of the primary (and other secondary) outcome findings?
Outcomes with similar pathophysiology (e.g. myocardial infarction and ischemic stroke with antihypertensive agents) should move in the same direction (both increased or both decreased), whereas outcomes with opposing pathophysiology (e.g. myocardial infarction and bleeding with antiplatelets) should move in opposite directions.
Was there an unexpected positive finding for a rare outcome?
One should be skeptical whenever an unexpected statistically significant reduction is found in a rare secondary outcome, particularly when there is no difference in the primary outcome.
A primary outcome is an outcome from which trial design choices are based (e.g. sample size calculations). Primary outcomes are not necessarily the most important outcomes.
A secondary outcome is any outcome that is not a primary outcome (i.e. secondary outcomes are not the focal point of design choices like sample size). Secondary outcomes may be more clinically important than the primary outcome.
This is the most accessible healthcare setting where generalist services are provided. For example, a family medicine clinic.
Randomized controlled trials are those in which participants are randomly allocated to two or more groups which are given different treatments.
