103
Metadata
“Metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource. Metadata is often called data about data or information about information.” (NISO, Understanding Metadata, 2004). Metadata allows us to understand the details of a dataset, including where it was collected, how it was collected, what gaps in the data mean, what the units of measurement are, who collected the data, how it should be attributed etc. By creating and providing good descriptive metadata for our own data, it enables others to efficiently discover and use the data products from our research.
In order to implement open data you need to include metadata that is essential for data discovery, sharing and reuse. Metadata provides a description of the study, files and variables answering the questions:
- Who created the data?
- What is the content of the data?
- When were the data created?
- Where is it geographically?
- How were the data developed?
- Why were the data developed?
There are three types of metadata:
- Descriptive: Provides information about the data that will help people find or understand in the dataset and the context. Project title, authors, keywords and collection methods are all types of descriptive metadata. Be sure to describe your variables giving them clear names. Name files with basic metadata file names.
- Administrative: Provides technical, preservation and rights information. It answers questions about what software is required to use the data and what license is attached to the data. File type, file size, copyright status and license terms are all examples of administrative metadata
- Structural: Provides information about how the data files relate to one another? You can link between data files and link to the related publication.
An established metadata standard will provide common terms, definitions, and structure and may vary depending on the repository you select. Each repository will have their own standard, but will be consistent in common terminology, definitions, language and structure. Good metadata ensures that your files are human and machine readable. Different disciplines may have their own standards or have adopted a specific metadata standard.
When you deposit your data into a repository, metadata fields are required to be completed as part of your deposit. The amount of metadata provided will enhance discovery.
Adapted from the Data Management Skill Building Hub and UBC Library’s Research Data Management workshop used under the Public Domain License
Test Your Knowledge
https://pressbooks.bccampus.ca/pose/wp-admin/admin-ajax.php?action=h5p_embed&id=3File Naming and Structure
When creating and collecting your data file naming and structure are important pieces of managing your data to make it easier for others to use. In keeping with the FAIR principles data formats should be in an open format, unencrypted and uncompressed. An open format is non-proprietary so that the file can be opened using open software that is not owned by a specific company. For example, instead of saving to an Excel file save as a CSV or XML. Unencrypted data is easily accessible for anyone whereas encrypted data is secure and locked and would require a pass code or key to unlock the data. An uncompressed file is one that is stored in the original format and hasn’t been compressed into another format. The UK Data Archive provides a list of recommended formats.
File Naming Guidance
- Guidelines for organizing your data provide examples of file naming conventions and has guidance for folder hierarchies.
- Assign descriptive file names from DataOne complements the above link offering a little more description on what file names should reflect and why.
Readme Files
One of the easiest ways to describe your dataset is with a readme file.
A plain text readme file is a document that articulates your dataset’s relationships with other files, whether this be other data files, code, or a manuscript. It ensures that the data can be interpreted by researchers as it includes the contents and structure of the dataset and provides sufficient information so that the researcher(s) can determine if the data will be helpful or not for their own research.
A readme file might also be where you articulate your variable level metadata, for example, what does the column labeled var 1 contain? This information may alternatively be recorded in a separate data dictionary, codebook or other documentation format. The details of how variable level metadata are captured are often discipline specific and so beyond what we can get into here. However, a search in a disciplinary repository can provide examples for what is standard for your discipline.
Review the readme file from this example (ttps://doi.org/10.5061/dryad.5nb504n) deposited into Dryad, a discipline agnostic repository. As in the image below, open the drop down to reveal the files associated with the data. Review the readme files to see how the authors have provided guidance to interpret their dataset. Consider how one of the readme files helps interpret the related csv file. Also note the file naming allows you to associate the appropriate csv file with its related readme.
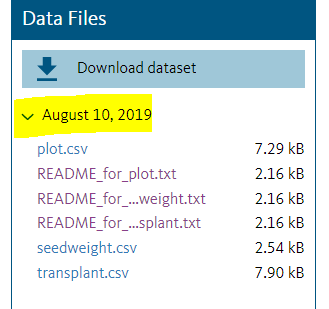
Solarik, Kevin A. et al. (2019), Data from: Local adaptation of trees at the range margins impact range shifts in the face of climate change, Dryad, Dataset, https://doi.org/10.5061/dryad.j0t179b

Dig Deeper
- What is the difference between readme, data dictionary, and codebook and how do they relate? See Readme, Data Dictionaries, Codebooks
Additional reading:
- Disciplinary Metadata. Search by discipline and resource type.
- Data repositories by discipline
- Creating a README for your dataset. A quick guide created by UBC Library covering the essentials.